Apache Synapse ESB - Configuration |
An Apache Synapse Enterprise Service Bus (ESB) engine is driven off a set of simple text/xml configuration files. This allows the configuration to be easily hand edited, backed up from the file system, or even included into version control for easier management and control (e.g. moving a configuration from development, through QA, staging and into production). The configuration files that drives the Synapse ESB are as follows:
While the axis2.xml configures the underlying transport and Web services support, the synapse.xml configures the mediation rules and configuration for the ESB. While any changes performed on the axis2.xml requires a restart (e.g. for enabling a transport such as JMS), the synapse.xml could be made to reference different configuration elements off a set of multiple files - that are served through the built-in Registry. When using the Registry to hold pieces of the configuration, certain elements such as endpoint definitions, sequences and local entries could be updated dynamically while the Synapse ESB executes, the the Registry could trigger a re-load as configured.
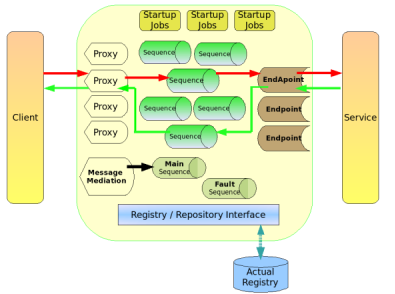
As the diagram below depicts, the Synapse configuration defines the Proxy services, Endpoints, Sequences and Startup jobs managed by the Synapse ESB. It also defines the interface to the Registry/Repository being used by the engine. Typically the Synapse ESB is deployed between the actual client and a backend service implementation to mediate the message flow in between. Thus the Synapse ESB can accept a message on behalf of the actual service, perform authentication, validation, transformation, logging, routing based on the content etc. and then decide the destination target endpoint for the message and direct it to an actual service implementation. The Synapse ESB can also detect timeouts, transport failures during communication or introduce load balancing, throttling or caching where necessary. For fault scenarios such as authentication failure, or schema validation failure, the Synapse ESB can be configured to return a custom message or a fault to the requesting client without forwarding the request to the actual service.
The Synapse ESB can operate in two modes:
In Service mediation, the Synapse ESB exposes a service endpoint on the ESB, that accepts messages from clients. Typically these services acts as proxies for existing (external) services, and the role of Synapse would be to "mediate" these messages before they are proxied to the actual service. In this mode, Synapse could expose a service already available in one transport, over a different transport; or expose a service that uses one schema or WSDL as a service that uses a different schema or WSDL etc. A Proxy service could define the transports over which the service is exposed, and point to the mediation sequences that should be used to process request and response messages through the proxy service. A proxy service maybe a SOAP or REST/POX service over http/s or SOAP, POX, Plain Text or Binary / Legacy service for other transports such as JMS and VFS file systems - e.g. CSV content being the payload
In Message mediation, Synapse can act as a transparent proxy for clients - if they are directed to point to the Synapse ESB as a http proxy. This way, Synapse could be configured to filter all messages on a network for logging, access control etc, and could "mediate" messages without the explicit knowledge of the original client. If Synapse receives a message that is not accepted by any proxy service, this message is handled through message mediation as well. Message mediation always processes messages according to the mediation sequence defined as "main".
The Synapse ESB defines a 'mediator' as a component that is performs some mediation action on a message during the process flow. Thus a mediator gets full access to a message at the point where it is defined to gain control, and could inspect the message, modify it or take an external action depending on some attributes or values of the current message. A mediation sequence, commonly called a 'sequence' is a list of such mediators. A sequence may be named for re-use, or defined in-line or anonymously within a configuration. Sequences may be defined within the synapse.xml configuration or within the Registry. Writing a custom mediator in Java is easy and the supplementary documentation provides more details on this. The 'Class' and 'POJO (command)" mediators allows one to plugin a Java class easily into the Synapse engine with minimal effort. In addition, the Script mediator allows one to provide an Apache BSF script (e.g. Javascript, Ruby, Groovy etc) for mediation.
A Synapse configuration holds two special sequences named as "main" and "fault". These may be defined within the synapse.xml, or externally via the Registry. If either is not found, a suitable default is generated at runtime by the ESB. The default "main" sequence will simple send a message without mediation, while the default "fault" sequence would log the message including the payload and any error/exception encountered and stop further processing. The 'fault' sequence executes whenever Synapse itself encounters an error while processing a message - or when a fault handler has not been defined to handle exceptions. A sequence can assign another named sequence as its "fault" handler sequence, and control branches to the fault handler if an error is encountered during the execution of the initial sequence.
An Endpoint definition within Synapse defines an external service endpoint and any attributes or semantics that should be followed when communicating with that endpoint. An endpoint definition can be named for re-use, or defined in-line or anonymously within a configuration. Typically an endpoint would be based on a service Address or a WSDL. Additionally the Synapse ESB supports Failover and Load-balance endpoints - which are defined over a group of endpoints. Endpoints may be defined within the synapse.xml configuration or within the Registry.
A Task is a custom Java class that implements the org.apache.synapse.startup.Task interface that defines a single "public void execute()" method. Such a task can be scheduled and managed via the Synapse ESB. The scheduling information for a task can be specified in the cron format or a simple format by the user. A task may also be specified as a one-time task where required, and can be used to trigger a callout or inject a message into the Synapse ESB.
A Synapse configuration can refer to an external Registry / Repository for resources used such as WSDL's, Schemas, Scripts, XSLT or XQuery transformations etc. One or more remote registries may be hidden or merged behind a local Registry interface defined to a Synapse configuration. Resources from an external registry are looked up using "keys" - which are known to the external registry. The Synapse ESB ships with a simple URL based registry implementation that uses the file system for storage of resources, and URL's or fragments as "keys".
A Registry may define a duration for which a resource served may be cached by the Synapse runtime. If such a duration is specified, the Synapse ESB is capable of refreshing the resource after cache expiry to support dynamic re-loading of resource at runtime. Optionally, a configuration could define certain "keys" to map to locally defined entities. These entities may refer to a source URL or file, or defined as in-line XML or text within the configuration itself. If a Registry contains a resource whose "key" matches the key of a locally defined entry, the local entry shadows the resource available in the Registry. Thus it is possible to override Registry resources locally from within a configuration. To integrate Synapse with a custom / new Registry or repository, one needs to implement the org.apache.synapse.registry.Registry interface to suit the actual Registry being used.
The axis2.xml file configures the underlying Axis2 web services engine for the Synapse ESB. The axis2.xml thus defines the transports enabled, and other configuration parameters associated. A change to the axis2 configuration requires a hard re-start of the Synapse ESB. By default the non-blocking http/s and the Apache VFS file system based transport are enabled for listening of messages, while the non-blocking http/s, VFS and JMS transports are enabled for sending messages out. Sample configurations to enable/configure the other transports are provided within the default axis2.xml file, and can be easily uncommented and modified. The sample JMS configuration shipped is for a default ActiveMQ 4.1.x installation.
A Synapse configuration looks like the following at the top level:
<definitions> <registry provider="string">...</registry>? <localEntry key="string">...</localEntry>? <sequence name="string">...</sequence>? <endpoint name="string">...</endpoint>? <proxy name="string" ...>...</proxy>? <task name="string" ...>...</task>? mediator* </definitions>
The <definitions> elements in a synapse.xml holds the Synapse ESB configuration. While the <registry>, <sequence>, <endpoint>, <proxy>, <task> and <localEntry> elements refer to those discussed above, the built-in mediator elements names are already registered with the Synapse engine. Custom mediators written by a user may be included into the library directory, and would be dynamically picked up in a Sun JDK environment. A list of mediators found directly as children under the <definitions> element would be treated as the "main" sequence, if a named sequence with the name "main" cannot be found.
The <registry> element is used to define the remote registry used by the configuration. The registry provider specifies an implementation class for the registry implementation used, and optionally a number of configuration parameters as may be required for the configuration of the connection to the registry.
<registry provider="string"/> <parameter name="string">text | xml</parameter>* </registry>
Registry entries loaded from a remote registry may be cached as dictated by the registry, and reloaded after the cache periods expires if a newer version is found. Hence it is possible to define configuration elements such as (dynamic) sequences and endpoints, as well as resources such as XSLT's, Scripts or XSDs off the registry, and update the configuration as these are allowed to dynamically change over time.
Synapse ships with a built-in URL based registry implementation called the "SimpleURLRegistry" and this can be configured as follows:
e.g. <registry provider="org.apache.synapse.registry.url.SimpleURLRegistry"> <parameter name="root">file:./repository/conf/sample/resources/</parameter> <parameter name="cachableDuration">15000</parameter> </registry>
The "root" parameter specifies the root URL of the Registry for loaded resources. The SimpleURLRegistry keys are path fragments, that when combined with the root prefix would form the full URL for the referenced resource. The "cachableDuration" parameter specifies the number of milliseconds for which resources loaded from the Registry should be cached. More advanced registry implementations allows different cachable durations to be specified for different resources, or mark some resources as never expires. (e.g. Check the WSO2 ESB implementation built over the Apache Synapse ESB core)
The <localEntry> element is used to declare registry entries that are local to the Synapse instance, as shown below
<localEntry key="string" [src="url"]>text | xml</localEntry>
These entries are top level entries which are globally visible within the entire system. Values of these entries can be retrieved via the extension XPath function "synapse:get-property(prop-name)" and the keys of these entries could be specified wherever a registry key is expected within the configuration.
An entry can be static text specified as inline text or static XML specified as an inline XML fragment or specified as a URL (using the src attribute). A local entry shadows any entry with the same name from a remote Registry.
e.g.
<localEntry key="version">0.1</localEntry>
<localEntry key="validate_schema">
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
...
</xs:schema>
</localEntry>
<localEntry key="xslt-key-req" src="file:repository/conf/sample/resources/transform/transform.xslt"/>
A <sequence> element is used to define a sequence of mediators that can be invoked later by name. The sequences named "main" and "fault" has special significance in a Synapse configuration. The "main" sequence handles any message that is accepted for 'Message Mediation', and the "fault" sequence is invoked if Synapse encounters a fault, and a custom fault handler is not specified for the sequence via its "onError" attribute. If the "main" or "fault" sequences are not defined locally or not found in the Registry, the Synapse ESB defines suitable defaults at initialization.
A Dynamic Sequence may be defined by specifying a key reference to a registry entry. As the remote registry entry changes, the sequence will dynamically be updated according to the specified cache duration and expiration. If tracing is enabled on a sequence, all messages being processed through the sequence would write tracing information through each mediation step to the trace.log file configured via the log4j.properties configuration. Setting the trace log level to TRACE would additionally dump the message and detailed trace information at each mediation step. A tracing enabled sequence propagates this setting to invoked sub-sequences.
<sequence name="string" [onError="string"] [key="string"] [trace="enable"]> mediator* </sequence>
e.g. <sequence name="main" onError="errorHandler"> .. <!-- a 'main' sequence that invokes the sequence named 'errorHandler' on a fault --> .. </sequence>
<sequence key="sequence/dynamic_seq_1.xml"/> where "sequence/dynamic_seq_1.xml" refers to the following sequence definition from the registry: <sequence name="dynamic_sequence" xmlns="http://ws.apache.org/ns/synapse"> .. </sequence>
An <endpoint> element defines a destination for an outgoing message. An endpoint may be specified as an address endpoint, WSDL based endpoint, a load balancing endpoint or a fail-over endpoint as follows:
<endpoint [name="string"] [key="string"] [trace="enable"]> address-endpoint | wsdl-endpoint | load-balanced-endpoint | fail-over-endpoint </endpoint>
All above endpoint types can have a name attribute, and such named endpoints can be reffered by other endpoints, through the key attribute. For example if there is an endpoint named as "foo", the following endpoint can be used in any place, where "foo" has to be used.
<endpoint key="foo"/>
The "trace" attribute turns on detailed trace information for messages being sent to the endpoint. These are available in the trace.log configured via the log4j.properties file. Setting the trace log level to TRACE will dump detailed trace information including message payloads.
Address endpoint is an endpoint defined by specifying the EPR and other attributes of the endpoint directly in the configuration.The 'uri' attribute of the address element contains the EPR of the target endpoint. Message format for the endpoint and the method to optimize attachments can be specified in the format and optimize attributes respectively. Reliable messaging and security policies for the endpoint can be specified in the policy attribute of the enableRM and enableSec elements respectively. WS-Addressing can be engaged for the messaging going to the endpoint by the enableAddressing element. suspendDurationOnFailure attribute specifies the time duration in seconds to suspend this endpoint, if it is detected as failed. If this attribute is not specified, endpoint will never be recovered after a failure.
Address endpoints can timeout if responses fail to arrive at Synapse by a predefined timeout-duration specified in seconds. The timeout action specifies whether to discard responses that arrives late, or to trigger a fault. Synapse has a periodic timeout handler that triggers itself at each 15 second interval. Thus endpoint timeouts will have a +/- error on actual trigger time. Though this can be minimized by setting a System property "synapse.timeout_handler_interval" to a millisecond duration below the desired endpoint timeout, care must be taken as a lesser value may have a higher overhead on the system.
An endpoint that fails may be suspended for a specified duration after such a failure, during which new messages will not be processed through the endpoint. The 'suspendDurationOnFailure' could specify an optional value in seconds for which this endpoint should be suspended.
QoS aspects such as WS-RM and WS-Security and WS-Addressing may be enabled on messages sent to an endpoint using the enableRM, enableSec and enableAddressing elements. Optionally, the WS-RM and WS-Security policies could be specified using the 'policy' attributes.
<address uri="endpoint-address" [format="soap11|soap12|pox|get"] [optimize="mtom|swa"]>
<enableRM [policy="key"]/>?
<enableSec [policy="key"]/>?
<enableAddressing/>?
<suspendDurationOnFailure>suspend-duration</suspendDurationOnFailure>?
<timeout>
<duration>timeout-duration</duration>
<action>discard|fault</action>
</timeout>?
</address>
Following are some sample address URI definitions.
e.g.
HTTP http://localhost:9000/soap/SimpleStockQuoteService
JMS jms:/SimpleStockQuoteService?transport.jms.ConnectionFactoryJNDIName=QueueConnectionFactory&
java.naming.factory.initial=org.apache.activemq.jndi.ActiveMQInitialContextFactory&
java.naming.provider.url=tcp://localhost:61616&transport.jms.DestinationType=topic
Mail mailto:guest@host
File vfs:file:///home/user/directory
vfs:file:///home/user/file
vfs:ftp://guest:guest@localhost/directory?vfs.passive=true
WSDL endpoint is an endpoint definition based on a specified WSDL document. The WSDL document can be specified either as a URI or as an inlined definition within the configuration. The service and port name containing the target EPR has to be specified with the 'service' and 'port' (or 'endpoint') attributes respectively. enableRM, enableSec, enableAddressing, suspendDurationOnFailure and timeout elements are same as for an Address endpoint.
<wsdl [uri="wsdl-uri"] service="qname" port/endpoint="qname">
<wsdl:definition>...</wsdl:definition>?
<wsdl20:description>...</wsdl20:description>?
<enableRM [policy="key"]/>?
<enableSec [policy="key"]/>?
<enableAddressing/>?
<suspendDurationOnFailure>suspend-duration</suspendDurationOnFailure>?
<timeout>
<duration>timeout-duration</duration>
<action>discard|fault</action>
</timeout>?
</wsdl>
A Load balanced endpoint distributes the messages (load) arriving at it among a set of listed endpoints by evaluating the load balancing policy and any other relevant parameters. Policy attribute of the load balance element specifies the load balance policy (algorithm) to be used for selecting the target endpoint. Currently only the roundRobin policy is supported. failover attribute determines if the next endpoint should be selected once the currently selected endpoint has failed, and defaults to true. The set of endpoints among which the load is distributed can be listed under the 'loadBalance' element. Those endpoints can belong to any endpoint type mentioned in this document. For example, failover endpoints can be listed inside the load balance endpoint to load balance between failover groups etc.
The optional 'session' element makes the endpoint a session affinity based load balancing endpoint. If it is specified, sessions are bound to endpoints in the first message and all successive messages for those sessions are directed to their associated endpoints. Only http sessions are currently supported, and identifies sessions based on http cookies. The 'failover' attribute mentioned above is not applicable for session affinity based endpoints and it is always considered as set to false. If it is required to have failover behavior in session affinity based load balance endpoints, list failover endpoints as the target endpoints.
<session type="http"/>? <loadBalance [policy="roundRobin"] [failover="true|false"]> <endpoint .../>+ </loadBalance>
Failover endpoints send messages to the listed endpoints with the following failover behavior. At the start, the first listed endpoint is selected as the primary and all other endpoints are treated as backups. Incoming messages are always sent only to the primary endpoint. If the primary endpoint fails, next active endpoint is selected as the primary and failed endpoint is marked as inactive. Thus it sends messages successfully as long as there is at least one active endpoint among the listed endpoints.
<failover> <endpoint .../>+ </failover>
A <proxy> element is used to define a Synapse Proxy service.
<proxy name="string" [transports="(http |https |jms |.. )+|all"] [pinnedServers="(serverName )+"]>
<description>...</description>?
<target [inSequence="name"] [outSequence="name"] [faultSequence="name"] [endpoint="name"]>
<inSequence>...</inSequence>?
<outSequence>...</outSequence>?
<faultSequence>...</faultSequence>?
<endpoint>...</endpoint>?
</target>?
<publishWSDL key="string" uri="string">
<description>...</description> | <definitions>...</definitions>
</publishWSDL>?
<enableSec/>?
<enableRM/>?
<policy key="string">...</policy>? // optional service level policies such as (e.g. WS-Security and/or WS-RM policies)
<parameter name="string"> // optional service parameters such as (e.g. transport.jms.ConnectionFactory)
string | xml
</parameter>
</proxy>
A proxy service is created and exposed on the specified transports through the underlying Axis2 engine, exposing service EPR's as per the standard Axis2 conventions - based on the service name. (Note: that currently Axis2 does not allow custom URI's to be set for services on some transports such as http/s) The Proxy service could be exposed over all enabled Axis2 transports such as http, https, JMS, Mail and File etc. or on a subset of these as specified with the optional 'transports' attribute.
You can give a list of synapse server names where this proxy service should be deployed using 'pinnedServers' attribute. It takes the server names separated by comma or space character. If there is no pinned server list then proxy service will be started in all server instances. If a pinned server names list is given it will only start in the given named Synapse server instances. The Synapse server name picked up from the system property 'SynapseServerName', failing which the hostname of the machine would be used or default to 'localhost'. You can give a name to a Synapse server instance as ./synapse.sh -DSynapseServerName=<ServerName> or by editing the wrapper.conf where Synapse is started as a service.
Each service could define the target for received messages as a named sequence or a direct endpoint. Target inSequence or endpoint is required for the proxy configuration, and a target outSequence defines how responses should be handled. Any supplied WS-Policies would apply as service level policies, and any service parameters could be passed into the proxy services' AxisService instance using the parameter elements (e.g. the JMS destination etc). If the proxy service should enable WS-Reliable Messaging or Security, the appropriate modules could be engaged, and specified service level policies will apply.
A Dynamic Proxy may be defined by specifying the properties of the proxy as dynamic entries by refering them with the key. (For example one could specify the inSequence or endpoint with a remote key, without defining it in the local configuration) As the remote registry entry changes, the properties of the proxy will dynamically be updated accordingly. (Note: proxy service definition itself can not be specified to be dynamic; i.e <proxy key="string"/> is wrong)
You can give the following as service parameters:
| Parameter | Value | Default | Description |
|---|---|---|---|
| useOriginalwsdl | true|false | false | Use the given WSDL instead of generating the WSDL. |
| modifyUserWSDLPortAddress | true|false | true | (Effective only with useOriginalwsdl=true) If true (default) modify the port addresses to current host. |
Transport specific parameters that may be set as service parameters:
| Transport | Require | Parameter | Description |
|---|---|---|---|
| JMS | Optional | transport.jms.ConnectionFactory | The JMS connection factory definition (from axis2.xml) to be used to listen for messages for this service |
| Optional | transport.jms.Destination | The JMS destination name (Defaults to the service name) | |
| Optional | transport.jms.DestinationType | The JMS destination type. Accept values 'queue' or 'topic' | |
| Optional | transport.jms.ReplyDestination | The destination where a reply will be posted | |
| VFS | Required | transport.vfs.FileURI | The primary File (or Directory) URI in the vfs* transport format, for this service |
| Required | transport.vfs.ContentType | The content type for messages for this service | |
| Optional | transport.vfs.FileNamePattern | A file name regex pattern to match files against a directory specified by the FileURI | |
| Optional | transport.PollInterval | The poll interval (in seconds) | |
| Optional | transport.vfs.ActionAfterProcess | DELETE or MOVE | |
| Optional | transport.vfs.MoveAfterProcess | The directory to move files after processing (i.e. all files process successfully) | |
| Optional | transport.vfs.ActionAfterErrors | DELETE or MOVE | |
| Optional | transport.vfs.MoveAfterErrors | The directory to move files after errors (i.e. some of the files succeed but some fail) | |
| Optional | transport.vfs.ActionAfterFailure | DELETE or MOVE | |
| Optional | transport.vfs.MoveAfterFailure | The directory to move after failure (i.e. all files fail) | |
| Optional | transport.vfs.ReplyFileURI | Reply file URI | |
| Optional | transport.vfs.ReplyFileName | Reply file name (defaults to response.xml) | |
VFS Transport URI examples (See http://commons.apache.org/vfs/filesystems.html for more samples)
file:///directory/filename.ext file:////somehost/someshare/afile.txt jar:../lib/classes.jar!/META-INF/manifest.mf jar:zip:outer.zip!/nested.jar!/somedir ftp://myusername:mypassword@somehost/pub/downloads/somefile.tgz[?vfs.passive=true]
A <task> element is used to define a Synapse Startup Task.
<task class="mypackage.MyTask" name="string" [pinnedServers="(serverName)+"]>
<property name="stringProp" value="String"/>
<property name="xmlProp">
<somexml>config</somexml>
</property>
<trigger ([[count="10"]? interval="1000"] | [cron="0 * 1 * * ?"] | [once=(true | false)])/>
</task>
A task is created and scheduled to run at specified time intervals or as specified by the cron expression. The Task class specifies the actual task implementation class (which must implement org.apache.synapse.startup.Task interface) to be executed at the specified interval/s, and name specifies an identifier for the scheduled task.
Fields in the task class can be set using properties provided as string literals or as XML fragments. (For example; if the task implementation class has a field named "version" with a corresponding setter method, the configuration value which will be assigned to this field before running the task can be specified using a property with the name 'version')
There are three different trigger mechanisms to schedule tasks. A simple trigger is specified specifying a 'count' and an 'interval', implying that the task will run a 'count' number of times at specified intervals. A trigger may also be specified as a cron trigger using a cron expression. A one-time trigger is specified using the 'once' attribute as true in the definition and could be specified as true in which case this task will be executed only once just after the initialization of Synapse
You can give a list of synapse server names where this task should be started using pinnedServers attribute. Refer to the explanation of this attribute under proxy services for more information.
A mediator token refers to any of the following tokens:
send | drop | log | property | sequence | validate | makefault | xslt | header | filter | switch | in | out
| dblookup | dbreport | RMSequence | throttle | xquery | cache | clone | iterate | aggregate | class | pojoCommand | script | spring
In addition to the above, Synapse will be able to load custom mediators via the J2SE Service Provider model. Mediator extensions must implement the MediatorFactory interface. The Class and POJO Command mediators allow custom Java code to be easily invoked during mediation, while the Script mediator allows Apache BSF scripts such as Javascript, Ruby, Groovy etc to be used for mediation.
The send token represents a <send> element, used to send messages out of Synapse to some endpoint. The send mediator also copies any message context properties from the current message context to the reply message received on the execution of the send operation so that the response could be correlated back to the request. Messages may be correlated by WS-A MessageID, or even simple custom text labels (see the property mediator and samples)
In the simplest case shown below, the destination to send a message is implicit in the message via the 'To' address. Thus a request message will be sent to its 'To' address, and a response message would be sent back to the client. Removing the 'To' address of a message targets it back to the client, and thus a request message received may be returned to the client after changing its direction. (Note: to mark a message as a response set the property RESPONSE to true)
Note: A send operation may be blocking or non-blocking depending on the actual transport implementation used. As the default NIO based http/s implementation does not block on a send, care must be taken if the same message must be sent and then further processed (e.g. transformed). In such a scenario, it maybe required to first clone the message into two copies and then perform processing to avoid conflicts.
<send/>
If the message is to be sent to one or more endpoints, then the following is used:
<send> (endpointref | endpoint)+ </send>
where the endpointref token refers to the following:
<endpoint key="name"/>
and the endpoint token refers to an anonymous endpoint definition.
The drop token refers to a <drop> element which is used to stop further processing of a message:
<drop/>
Once the <drop> mediator executes, further processing of the current message stops. A the drop mediator does not necessarily close transports.
The log token refers to a <log> element which may be used to log messages being mediated:
<log [level="string"] [separator="string"]> <property name="string" (value="literal" | expression="xpath")/>* </log>
The optional level attribute selects a pre-defined subset of properties to be logged.
e.g.
A separator if defined will be used to separate the attributes being logged. The default separator is the ',' comma.
<property name="string" [action=set|remove] (value="literal" | expression="xpath") [scope=transport|axis2|axis2-client]/>
The property token refers to a <property> element which is a mediator that has no direct impact on the message but rather on the message context flowing through Synapse. The properties set on a message can be later retrieved through the synapse:get-property(prop-name) XPath extension function. If a scope is specified for a property, the property could be set as a transport header property or an (underlying) Axis2 message context property, or as a Axis2 client option. If a scope is not specified, it will default to the Synapse message context scope. Using the property element with action specified as "remove" you can remove any existing message context properties.
There are some well-defined properties that you can get/set on the Synapse message context scope:
There are some Axis2 and module properties that are useful which are set at scope="axis2"
There are some Axis2 client side properties/options that are useful which are set at scope="axis2-client"
The get-property() function allows any XPath expression used in a configuration to lookup information from the current message context. It is possible to retrieve properties previously set with the property mediator, and/or information from the Synapse or Axis2 message contexts or transport header. The function accepts the scope as an optional parameter as shown below:
synapse:get-property( [(axis2 | axis2-client | transport),] <property_name> [,<dateformat>] )
Some useful properties from the Synapse message context follows:
In addition to the above, one may use the get-property() function to retrieve Axis2 message context properties or transport headers. e.g. synapse:get-property('transport', 'USER_AGENT')
<sequence key="name"/>
A sequence ref token refers to a <sequence> element which is used to invoke a named sequence of mediators.
<validate [source="xpath"]>
<property name="validation-feature-id" value="true|false"/>*
<schema key="string"/>+
<on-fail>
mediator+
</on-fail>
</validate>
The <validate> mediator validates the result of the evaluation of the source xpath expression, against the schema specified. If the source attribute is not specified, the validation is performed against the first child of the SOAP body of the current message. If the validation fails, the on-fail sequence of mediators is executed. Properties could be used to turn on/off some of the underlying features of the validator (See http://xerces.apache.org/xerces2-j/features.html)
<makefault [version="soap11|soap12"]> <code (value="literal" | expression="xpath")/> <reason (value="literal" | expression="xpath")> <node>? <role>? <detail>? </makefault>
The <makefault> mediator transforms the current message into a fault message, but does NOT send it. The <send> mediator needs to be invoked to send a fault message created this way. The fault message "to" header is set to the "faultTo" of the original message if such a header existed on the original message. If a 'version' attribute is specified, the created fault message will be created as a selected SOAP 1.1 or SOAP 1.2 fault.
<xslt key="string" [source="xpath"]> <property name="string" (value="literal" | expression="xpath")/>* <feature name="string" value="true| false" />* </xslt>
The <xslt> mediator applies the specified XSLT transformation to the selected element of the current message payload. If the source element is not specified, it defaults to the first child of the soap body. Optionally parameters (XSLT) could be passed into the transformations through the 'property' elements.The 'feature' elements defines any features which should be set to the TransformerFactory by explicitly. The feature 'http://ws.apache.org/ns/synapse/transform/feature/dom' turns on DOM based transformations instead of serializing elements into Byte streams and/or temporary files. Though this would be better in performance than using byte streams, sometimes it may not work for all transformations.
<header name="qname" (value="literal" | expression="xpath") [action="set"]/> <header name="qname" action="remove"/>
The <header> mediator sets or removes a specified header from the current soap infoset. Currently the set header only supports simple valued headers. In the future we may extend this to have XML structured headers by embedding the XML content within the element itself. The optional action attribute specifies whether the mediator should set or remove the header. If omitted, it defaults to a set-header.
<filter (source="xpath" regex="string") | xpath="xpath"> mediator+ </filter>
The <filter> mediator either test the given xpath expression as a boolean expression, or match the evaluation result of a source xpath expression as a String against the given regular expression. If the test succeeds, the filter mediator will execute the enclosed mediators in sequence.
<switch source="xpath">
<case regex="string">
mediator+
</case>+
<default>
mediator+
</default>?
</switch>
The <switch> mediator will evaluate the given source xpath expression into its string value, and match it against the given regular expressions. If the specified cases does not match and a default case exists, it will be executed.
<in>
mediator+ </in>
<out> mediator+ </out>
The In and Out mediators will execute the child mediators over the current message if the message matches the direction of the mediator. Hence all incoming messages would pass through the "<in>" mediators and vice versa.
<dblookup>
<connection>
<pool>
(
<driver/>
<url/>
<user/>
<password/>
|
<dsName/>
<icClass/>
<url/>
<user/>
<password/>
)
<property name="name" value="value"/>*
</pool>
</connection>
<statement>
<sql>select something from table where something_else = ?</sql>
<parameter [value="" | expression=""] type="CHAR|VARCHAR|LONGVARCHAR|NUMERIC|DECIMAL|BIT|TINYINT|SMALLINT|INTEGER|BIGINT|REAL|FLOAT|DOUBLE|DATE|TIME|TIMESTAMP"/>*
<result name="string" column="int|string"/>*
</statement>+
</dblookup>
The dblookup mediator is capable of executing an arbitrary SQL select statement, and then set some resulting values as local message properties on the message context. The DB connection used maybe looked up from an external DataSource or specified in-line, in which case an Apache DBCP connection pool is established and used. Apache DBCP connection pools support the following properties:
More than one statement may be specified, and the SQL statement may specify parameters which could be specified as values or XPath expressions. The types of parameters could be any valid SQL types. Only the first row of a result set will be considered and any others are ignored. The single <result> element contains the 'name' and the column' attributes. The 'name' attribute defines the name under which the result is stored in the Synapse message context, and the column attribute specifies a column number or name .
<dbreport>
<connection>
<pool>
(
<driver/>
<url/>
<user/>
<password/>
|
<dsName/>
<icClass/>
<url/>
<user/>
<password/>
)
<property name="name" value="value"/>*
</pool>
</connection>
<statement>
<sql>insert into something values(?, ?, ?, ?)</sql>
<parameter [value="" | expression=""] type="CHAR|VARCHAR|LONGVARCHAR|NUMERIC|DECIMAL|BIT|TINYINT|SMALLINT|INTEGER|BIGINT|REAL|FLOAT|DOUBLE|DATE|TIME|TIMESTAMP"/>*
</statement>+
</dblreport>
The dbreport mediator is very similar to the dblookup mediator, but writes information to a Database, using the specified insert SQL statement.
<RMSequence (correlation="xpath" [last-message="xpath"]) | single="true" [version="1.0|1.1"]/>
The <RMSequence> mediator can be used to create a sequence of messages to communicate via WS-Reliable Messaging with an WS-RM enabled endpoint (<enableRM>). The simple use case of this mediator is to specify a single="true" property, because this means that only one message is involved in the same sequence. However if multiple messages should be sent in the same sequence, the correlation property should be used with a XPath expression that selects an unique element value from the incoming message. With the result of the XPath expression, Synapse can group messages together that belong to the same sequence. To close the sequence neatly, for the last message of the sequence also an XPath expression should be specified. With the version attribute the WS-RM specification version to be used can be specified, 1.0 or 1.1.
<throttle [onReject="string"] [onAccept="string"] id="string">
(<policy key="string"/> | <policy>..</policy>)
<onReject>..</onReject>?
<onAccept>..</onAccept>?
</throttle>
The Throttle mediator can be used for rate limiting as well as concurrency based limiting. A WS-Policy dictates the throttling configuration and may be specified inline or loaded from the registry. Please refer to the samples document for sample throttling policies. The Throttle mediator could be added in the request path for rate limiting and concurrent access limitation. When using for concurrent access limitation, the same throttle mediator 'id' must be triggered on the response flow so that completed responses are deducted from the available limit. (i.e. two instances of the throttle mediator with the same 'id' attribute in the request and response flows). The 'onReject' and 'onAccept' sequence references or inline sequences define how accepted and rejected messages are to be handled.
<xquery key="string" [target="xpath"]>
<variable name="string" type="string" [key="string"] [expression="xpath"] [value="string"]/>?
</xquery>
The XQuery mediator can be used to perform an XQuery transformation. The 'key' attribute specifies the XQuery transformation, and the optional 'target' attribute specifies the node of the message that should be transformed. This defaults to the first child of the SOAP body of the payload. The 'variable' elements define a variable that could be bound to the dynamic context of the XQuery engine in order to access those variables through the XQuery script .
It is possible to specify just a literal 'value', or an XPath expression over the payload, or even specify a registry key or a registry key combined with an XPath expression that selects the variable. The name of the variable corresponds to the name of variable declaration in the XQuery script. The 'type' of the variable must be a valid type defined by the JSR-000225 (XQJ API).
The supported types are:
<cache id="string" [hashGenerator="class"] [timeout="seconds"] [scope=(per-host | per-mediator)]
collector=(true | false) [maxMessageSize="in-bytes"]>
<onCacheHit [sequence="key"]>
(mediator)+
</onCacheHit>?
<implementation type=(memory | disk) maxSize="int"/>
</cache>
The <cache> mediator will evaluate the hash value of an incoming message as described in the optional hash generator implementation (which should be a class implementing the org.wso2.caching.digest.DigestGenerator interface). The default hash generator is 'org.wso2.caching.digest.DOMHashGenerator'. If the generated hash value has been found in the cache then the cache mediator will execute the onCacheHit sequence which can be specified inline or referenced. The cache mediator must be specified with an 'id' and two instances with this same 'id' that correlates the response message into the cache for the request message hash. The optional 'timeout' specifies the valid duration for cached elements, and the scope defines if mediator instances share a common cache per every host instance, or per every cache mediator pair (i.e. 'id') instance. The 'collector' attribute 'true' specifies that the mediator instance is a response collection instance, and 'false' specifies that its a cache serving instance. The maximum size of a message to be cached could be specified with the optional 'maxMessageSize' attributes in bytes and defaults to unlimited. Finally the 'implementation' element may define if the cache is disk or memory based, and the 'maxSize' attribute defines the maximum number of elements to be cached.
<clone [continueParent=(true | false)]>
<target [to="uri"] [soapAction="qname"] [sequence="sequence_ref"] [endpoint="endpoint_ref"]>
<sequence>
(mediator)+
</sequence>?
<endpoint>
endpoint
</endpoint>?
</target>+
</clone>
The clone mediator closely resembles the Message Splitter EIP and will split the message into number of identical messages which will be processed in parallel. The original message cloned can be continued or dropped depending on the boolean value of the optional 'continueParent' attribute. Optionally a custom 'To' address and/or a 'Action' may be specified for cloned messages
<iterate [continueParent=(true | false)] [preservePayload=(true | false)] (attachPath="xpath")? expression="xpath">
<target [to="uri"] [soapAction="qname"] [sequence="sequence_ref"] [endpoint="endpoint_ref"]>
<sequence>
(mediator)+
</sequence>?
<endpoint>
endpoint
</endpoint>?
</target>+
</iterate>
The iterate mediator implements another EIP and will split the message into number of different messages derived from the parent message by finding matching elements for the XPath expression specified. New messages will be created for each and every matching element and processed in parallel using either the specified sequence or endpoint. Parent message can be continued or dropped in the same way as in the clone mediator. The 'preservePayload' attribute specifies if the original message should be used as a template when creating the splitted messages, and defaults to 'false', in which case the splitted messages would contain the split elements as the SOAP body.
<aggregate>
<correlateOn expression="xpath"/>?
<completeCondition [timeout="time-in-seconds"]>
<messageCount min="int-min" max="int-max"/>?
</completeCondition>?
<onComplete expression="xpath" [sequence="sequence-ref"]>
(mediator +)?
</onComplete>
</aggregate>
The aggregate mediator implements the Message Aggregator EIP and will aggregate the messages or responses for splitted messages using either the clone or iterate mediators. At the same time it can aggregate messages on the presence of matching elements specified by the correlateOn XPATH expression. Aggregate will collect the messages coming into it until the messages collected on the aggregation satisfies the complete condition. The completion condition can specify a minimum or maximum number of messages to be collected, or a timeout value in seconds, after which the aggregation terminates. On completion of the aggregation it will merge all of the collected messages and invoke the onComplete sequence on it. The merged message would be created using the XPath expression specified by the attribute 'expression' on the 'onComplete' element.
<class name="class-name">
<property name="string" value="literal">
(either literal or XML child)
</property>
</class>
The class mediator creates an instance of a custom specified class and sets it as a mediator. The class must implement the org.apache.synapse.api.Mediator interface. If any properties are specified, the corresponding setter methods are invoked on the class, once, during initialization.
<pojoCommand name="class-name">
(
<property name="string" value="string"/> |
<property name="string" context-name="literal" [action=(ReadContext | UpdateContext | ReadAndUpdateContext)]>
(either literal or XML child)
</property> |
<property name="string" expression="xpath" [action=(ReadMessage | UpdateMessage | ReadAndUpdateMessage)]/>
)*
</pojoCommand>
The pojoCommand mediator creates an instance of the specified command class - which may implement the org.apache.synapse.Command interface or should have a public void method "public void execute()". If any properties are specified, the corresponding setter methods are invoked on the class before each message is executed. It should be noted that a new instance of the POJO Command class is created to process each message processed. After execution of the POJO Command mediator, depending on the 'action' attribute of the property, the new value returned by a call to the corresponding getter method is stored back to the message or to the context. The 'action' attribute may specify whether this behaviour is expected or not via the Read, Update and ReadAndUpdate properties.
Synapse supports Mediators implemented in a variety of scripting languages such as JavaScript, Python or Ruby. There are two ways of defining script mediators, either with the script program statements stored in a separate file which is referenced via the local or remote registry entry, or with the script program statements embedded in-line within the Synapse configuration. A script mediator using a script off the registry (local or remote) is defined as follows:
<script key="string" language="string" [function="script-function-name"]/>
The property key is the registry key to load the script. The language attribute specifies the scripting language of the script code (e.g. "js" for Javascript, "rb" for ruby, "groovy" for Groovy, "py" for Python..). The function is an optional attribute defining the name of the script function to invoke, if not specified it defaults to a function named 'mediate'. The function is passed a single parameter - which is the Synapse MessageContext. The function may return a boolean, if it does not, then true is assumed, and the script mediator returns this value. An inline script mediator has the script source embedded in the configuration as follows:
<script language="string">...script source code...<script/>
The execution context environment of the script has access to the Synapse MessageContext predefined in a script variable named 'mc' . An example of an inline mediator using JavaScript/E4X which returns false if the SOAP message body contains an element named 'symbol' which has a value of 'IBM' would be:
<script language="js">mc.getPayloadXML()..symbol != "IBM";<script/>
Synapse uses the Apache Bean Scripting Framework for the scripting language support, any script language supported by BSF may be used to implement a Synapse Mediator.
Implementing a Mediator with a script language can have advantages over using the built in Synapse Mediator types or implementing a custom Java class Mediator. Script Mediators have all the flexibility of a class Mediator with access to the Synapse MessageContext and SynapseEnvironment APIs, and the ease of use and dynamic nature of scripting languages allows rapid development and prototyping of custom mediators. An additional benefit of some scripting languages is that they have very simple and elegant XML manipulation capabilities, for example JavaScript E4X or Ruby REXML, so this makes them well suited for use in the Synapse mediation environment. For both types of script mediator definition the MessageContext passed into the script has additional methods over the standard Synapse MessageContext to enable working with the XML in a way natural to the scripting language. For example when using JavaScript getPayloadXML and setPayloadXML, E4X XML objects, and when using Ruby, REXML documents.
The Synapse configuration language could be easily extended, with configuration extensions as well as mediation extensions. The Spring mediator is such an example.
A Spring configuration could be created as a localEntry or remote registry entry providing a URL or a key reference to a Registry. The configuration is then created on first use or as necessary (as per registry lookup semantics) by the mediators which reference this configuration.
<localEntry key="string"/> <localEntry key="string" src="url"/>
The name attribute specifies a unique name for the configuration, and the src, key or inlined XML references to the Spring configuration
<spring:spring bean="exampleBean1" key="string"/>
The <spring> element creates an instance of a mediator, which is managed by Spring. This Spring bean must implement the Mediator interface for it to act as a Mediator. The key will reference the Spring ApplicationContext/Configuration used for the bean