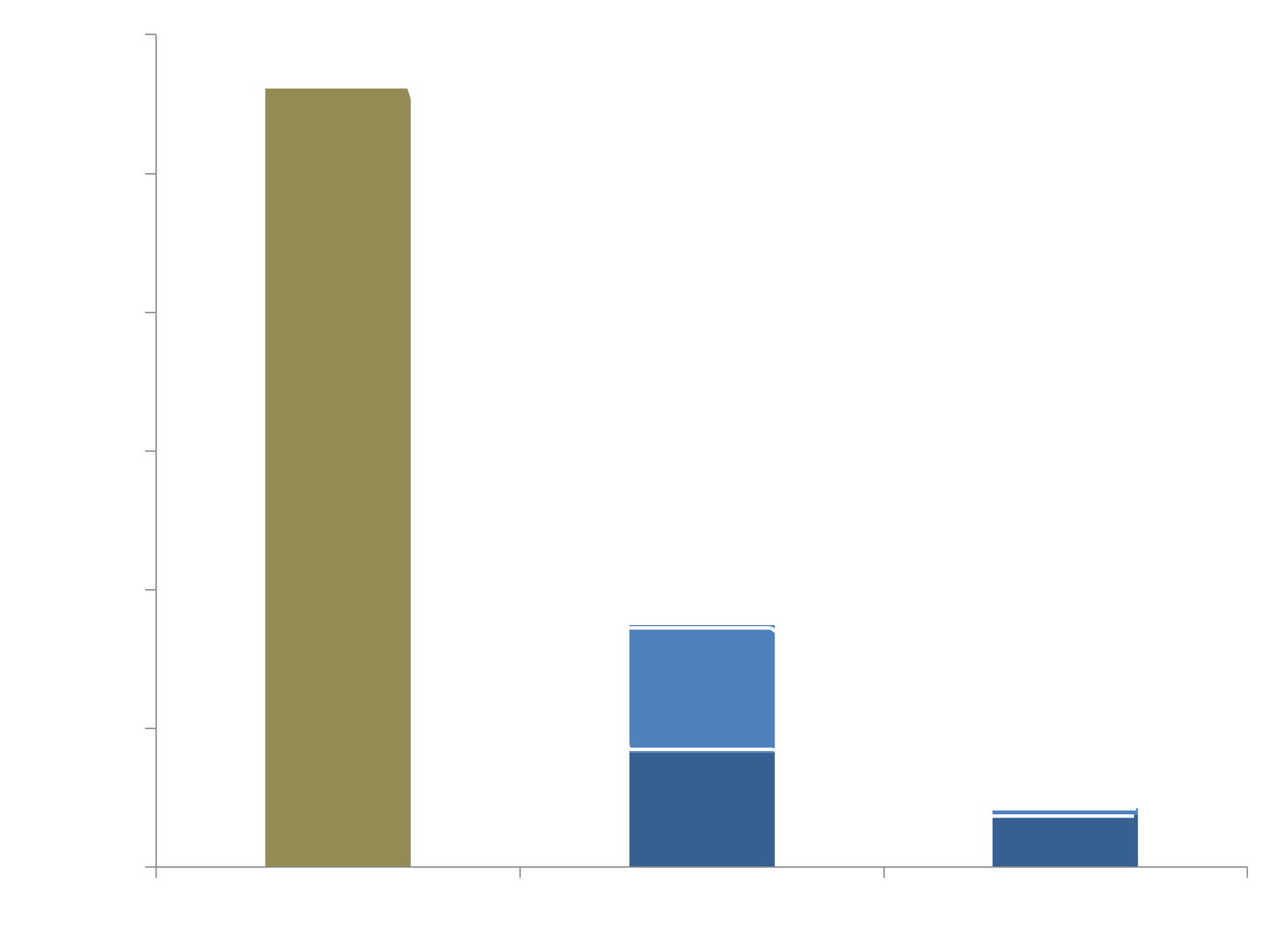
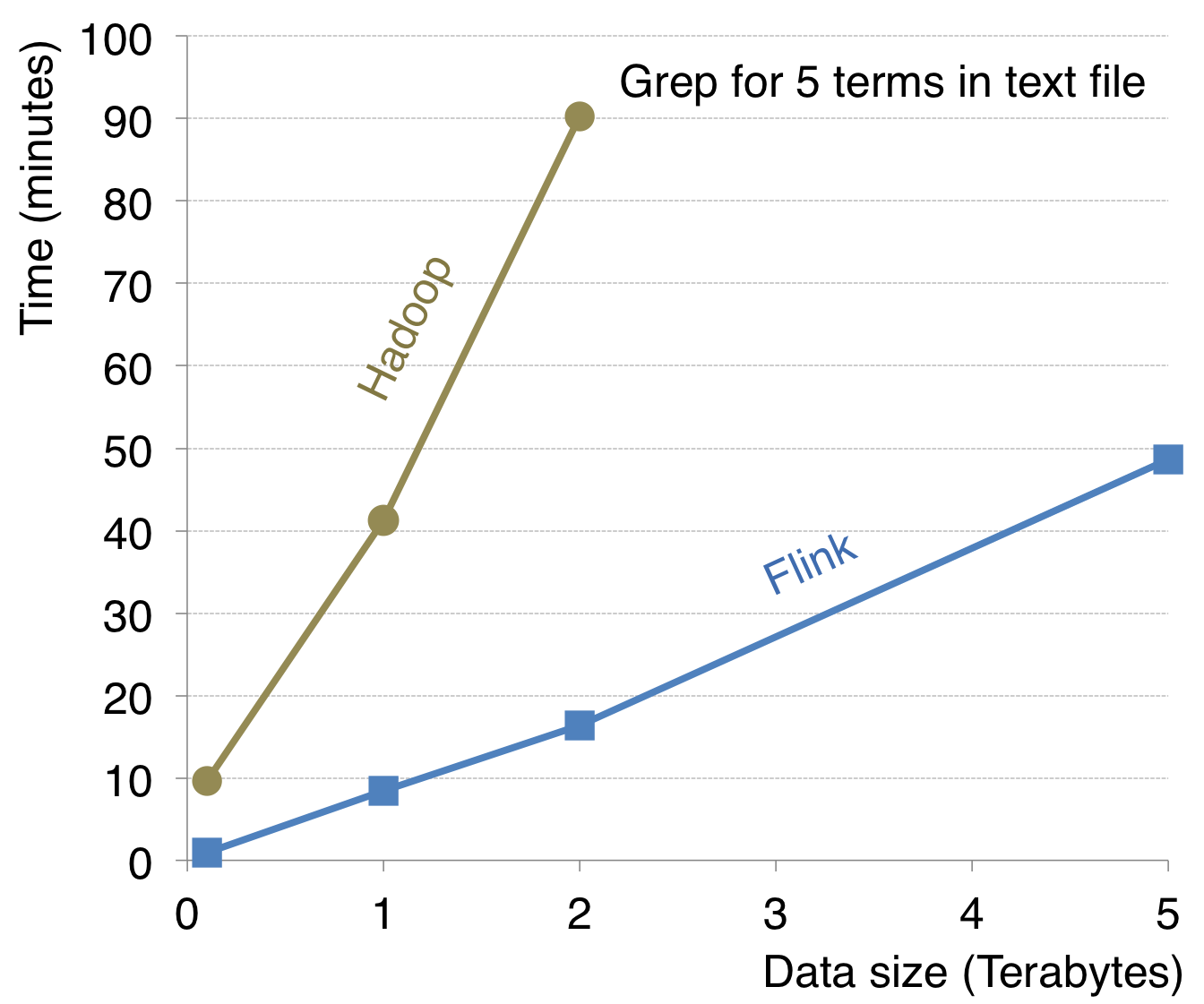
State-of-the art performance exploiting in-memory processing and data streaming.
Flink is designed to perform very well even when the cluster's memory runs out.
Write beautiful, type-safe code in Java and Scala. Execute it on a cluster.
Few configuration parameters required. Cost-based optimizer built in.
Tested on clusters of 100s of machines, Google Compute Engine, and Amazon EC2.
Flink runs on YARN and HDFS and has a Hadoop compatibility package.
Flink exploits in-memory data streaming and integrates iterative processing deeply into the system runtime.
This makes the system extremely fast for data-intensive and iterative jobs.
Flink is designed to perform well when memory runs out.
Flink contains its own memory management component, serialization framework, and type inference engine.
Tested in clusters of 100s of nodes, Amazon EC2, and Google Compute Engine.
Write beautiful, type-safe, and maintainable code in Java or Scala. Execute it on a cluster.
You can use native Java and Scala data types without packing them into key-value pairs, logical field addressing, and a wealth of operators.
Word Count in Flink's Scala API
case class Word (word: String, frequency: Int)
val counts = text
.flatMap {line => line.split(" ").map(word => Word(word,1))}
.groupBy("word").sum("frequency")Transitive Closure
case class Path (from: Long, to: Long)
val tc = edges.iterate(10) { paths: DataSet[Path] =>
val next = paths
.join(edges).where("to").equalTo("from") {
(path, edge) => Path(path.from, edge.to)
}
.union(paths).distinct()
next
}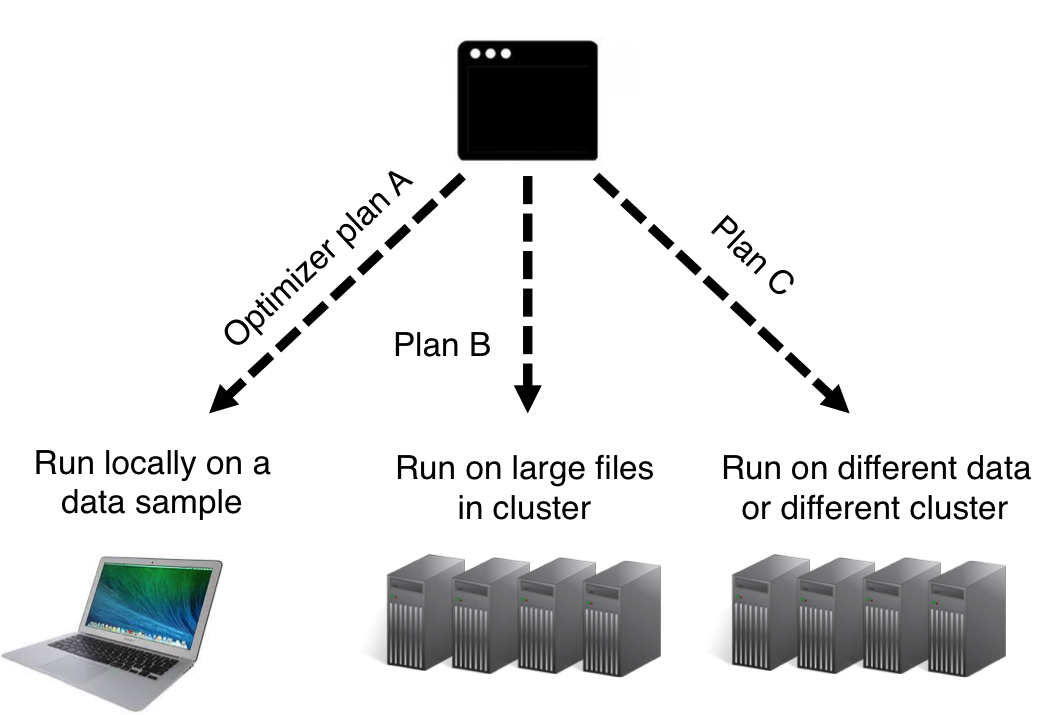
Flink requires few configuration parameters. And the system's bult-in optimizer takes care of finding the best way to execute the program in any enviroment.
Run on YARN with 3 commands, in a stand-alone cluster, or locally in a debugger.

Flink supports all Hadoop input and output formats and data types.
You can run your legacy MapReduce operators unmodified and faster on Flink.
Flink can read data from HDFS and HBase, and runs on top of YARN.
Flink contains APIs in Java and Scala for analyzing data from batch and streaming data sources, as well as its own optimizer and distributed runtime with custom memory management